Check the expression levels for DEGs found by GSFA
Kaixuan Luo
2022-08-20
Last updated: 2022-09-01
Checks: 7 0
Knit directory: GSFA_analysis/
This reproducible R Markdown analysis was created with workflowr (version 1.7.0). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
Great! Since the R Markdown file has been committed to the Git repository, you know the exact version of the code that produced these results.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(20220524) was run prior to running the code in the R Markdown file. Setting a seed ensures that any results that rely on randomness, e.g. subsampling or permutations, are reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Great job! Using relative paths to the files within your workflowr project makes it easier to run your code on other machines.
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility.
The results in this page were generated with repository version f255236. See the Past versions tab to see a history of the changes made to the R Markdown and HTML files.
Note that you need to be careful to ensure that all relevant files for the analysis have been committed to Git prior to generating the results (you can use wflow_publish or wflow_git_commit). workflowr only checks the R Markdown file, but you know if there are other scripts or data files that it depends on. Below is the status of the Git repository when the results were generated:
Ignored files:
Ignored: .Rhistory
Ignored: .Rproj.user/
Untracked files:
Untracked: Rplots.pdf
Untracked: analysis/check_Tcells_datasets.Rmd
Untracked: analysis/interpret_gsfa_LUHMES.Rmd
Untracked: analysis/interpret_gsfa_TCells.Rmd
Untracked: analysis/spca_LUHMES_data.Rmd
Untracked: analysis/test_seurat.Rmd
Untracked: code/gsfa_negctrl_job.sbatch
Untracked: code/music_LUHMES_Yifan.R
Untracked: code/plotting_functions.R
Untracked: code/run_gsfa_2groups_negctrl.R
Untracked: code/run_gsfa_negctrl.R
Untracked: code/run_music_LUHMES.R
Untracked: code/run_music_LUHMES_data.sbatch
Untracked: code/run_sceptre_LUHMES_data.sbatch
Untracked: code/run_sceptre_Tcells_stimulated_data.sbatch
Untracked: code/run_sceptre_Tcells_unstimulated_data.sbatch
Untracked: code/run_spca_LUHMES.R
Untracked: code/run_spca_TCells.R
Untracked: code/run_unguided_gsfa_LUHMES.R
Untracked: code/run_unguided_gsfa_LUHMES.sbatch
Untracked: code/run_unguided_gsfa_Tcells.R
Untracked: code/run_unguided_gsfa_Tcells.sbatch
Untracked: code/sceptre_LUHMES_data.R
Untracked: code/sceptre_Tcells_stimulated_data.R
Untracked: code/sceptre_Tcells_unstimulated_data.R
Untracked: code/seurat_sim_fpr_tpr.R
Untracked: code/unguided_GFSA_mixture_normal_prior.cpp
Unstaged changes:
Modified: analysis/sceptre_LUHMES_data.Rmd
Modified: analysis/twostep_clustering_LUHMES_data.Rmd
Modified: code/run_sceptre_cropseq_data.sbatch
Modified: code/sceptre_analysis.R
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the repository in which changes were made to the R Markdown (analysis/check_gsfa_deg_exp.Rmd) and HTML (docs/check_gsfa_deg_exp.html) files. If you’ve configured a remote Git repository (see ?wflow_git_remote), click on the hyperlinks in the table below to view the files as they were in that past version.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| Rmd | f255236 | kevinlkx | 2022-09-01 | added total number of DEGs |
| html | b60cbfd | kevinlkx | 2022-09-01 | Build site. |
| Rmd | 2aae326 | kevinlkx | 2022-09-01 | updated figure legend |
| html | cf9232c | kevinlkx | 2022-08-31 | Build site. |
| Rmd | b709053 | kevinlkx | 2022-08-31 | checked the distribution of DEGs by expression bins |
Load necessary packages and data
library(Seurat)
library(data.table)
library(Matrix)
library(tidyverse)
library(ggplot2)
theme_set(theme_bw() + theme(plot.title = element_text(size = 14, hjust = 0.5),
axis.title = element_text(size = 14),
axis.text = element_text(size = 12),
legend.title = element_text(size = 13),
legend.text = element_text(size = 12),
panel.grid.minor = element_blank())
)
library(gridExtra)
library(ComplexHeatmap)
library(kableExtra)
library(WebGestaltR)
library(GSFA)
source("/project2/xinhe/yifan/Factor_analysis/analysis_website_for_Kevin/scripts/plotting_functions.R")Set directories
res_dir <- "/project2/xinhe/kevinluo/GSFA/DEGs_by_expression_level"
dir.create(res_dir, recursive = TRUE, showWarnings = FALSE)LUHMES data
Load raw gene expression data
combined_obj <- readRDS("/project2/xinhe/yifan/Factor_analysis/shared_data/LUHMES_cropseq_data_seurat.rds")
dim(combined_obj)[1] 33694 8708Normalizing the data by log2 CPM
combined_obj <- NormalizeData(combined_obj, scale.factor = 1e6)
log2cpm_exp_mat <- GetAssayData(combined_obj) / log(2)
dim(log2cpm_exp_mat)[1] 33694 8708Select the 6k genes used for GSFA in this analysis
# Normalized and scaled data used for GSFA, the rownames of which are the 6k genes used for GSFA
scaled_gene_matrix_in_gsfa <- combined_obj@assays$RNA@scale.data
selected_gene_ids <- rownames(scaled_gene_matrix_in_gsfa)
log2cpm_exp_mat <- log2cpm_exp_mat[selected_gene_ids, ]
dim(log2cpm_exp_mat)[1] 6000 8708Load GSFA result
data_folder <- "/project2/xinhe/yifan/Factor_analysis/LUHMES/"
fit <- readRDS(paste0(data_folder,
"gsfa_output_detect_01/use_negctrl/All.gibbs_obj_k20.svd_negctrl.seed_14314.light.rds"))
gibbs_PM <- fit$posterior_means
lfsr_mat <- fit$lfsr[, -ncol(fit$lfsr)]
total_effect <- fit$total_effect[, -ncol(fit$total_effect)]
KO_names <- colnames(lfsr_mat)
guides <- KO_names[KO_names!="Nontargeting"]if(!all.equal(rownames(lfsr_mat), rownames(log2cpm_exp_mat))){stop("Gene names not match!")}
mean_gene_exp <- rowMeans(log2cpm_exp_mat)
exp_breaks <- quantile(mean_gene_exp, probs = seq(0,1,0.2))
gene_exp_bins <- cut(mean_gene_exp, breaks = exp_breaks, labels = 1:5)
gene_exp_bins[is.na(gene_exp_bins)] <- 1
gene_exp_bins.df <- data.frame(geneID = rownames(log2cpm_exp_mat), mean_exp = mean_gene_exp, exp_bin = gene_exp_bins)
table(gene_exp_bins.df$exp_bin)
lfsr_signif_num_bins <- data.frame()
for(l in 1:5){
curr_genes <- gene_exp_bins.df[gene_exp_bins.df$exp_bin == l, ]$geneID
cat(length(curr_genes), "genes in bin", l, "\n")
curr_lfsr_mat <- lfsr_mat[curr_genes, ]
curr_lfsr_signif_num <- colSums(curr_lfsr_mat < 0.05)
lfsr_signif_num_bins <- rbind(lfsr_signif_num_bins,
c(bin = l, curr_lfsr_signif_num))
}
colnames(lfsr_signif_num_bins) <- c("bin", colnames(lfsr_mat))
cat("Total number of DEGs: \n")
colSums(lfsr_signif_num_bins[,guides])
lfsr_signif_num_bins.df <- tidyr::gather(lfsr_signif_num_bins[,c("bin", guides)], guide, num_genes, all_of(guides), factor_key=TRUE)
lfsr_signif_num_bins.df$bin <- factor(lfsr_signif_num_bins.df$bin, levels = 1:5,
labels = c("[0-20%]", "[20-40%]", "[40-60%]", "[60-80%]", "[80-100%]"))
# pdf(file.path(res_dir, "LUHMES_stimulated_lfsr_signif_num_by_exp_bins.pdf"), width = 14, height = 3)
ggplot(lfsr_signif_num_bins.df, aes(x=guide, y=num_genes, fill=bin)) +
geom_bar(position="stack", stat="identity") +
scale_fill_brewer(palette = "Blues") +
guides(fill=guide_legend(title="Gene expression (log2 CPM) percentile")) +
labs(x = "Target genes",
y = "Number of DEGs",
title = "Number of DEGs detected by gene expression level") +
theme(axis.text.x = element_text(angle = 45, hjust = 1, size = 12),
legend.position = "right",
legend.text = element_text(size = 13))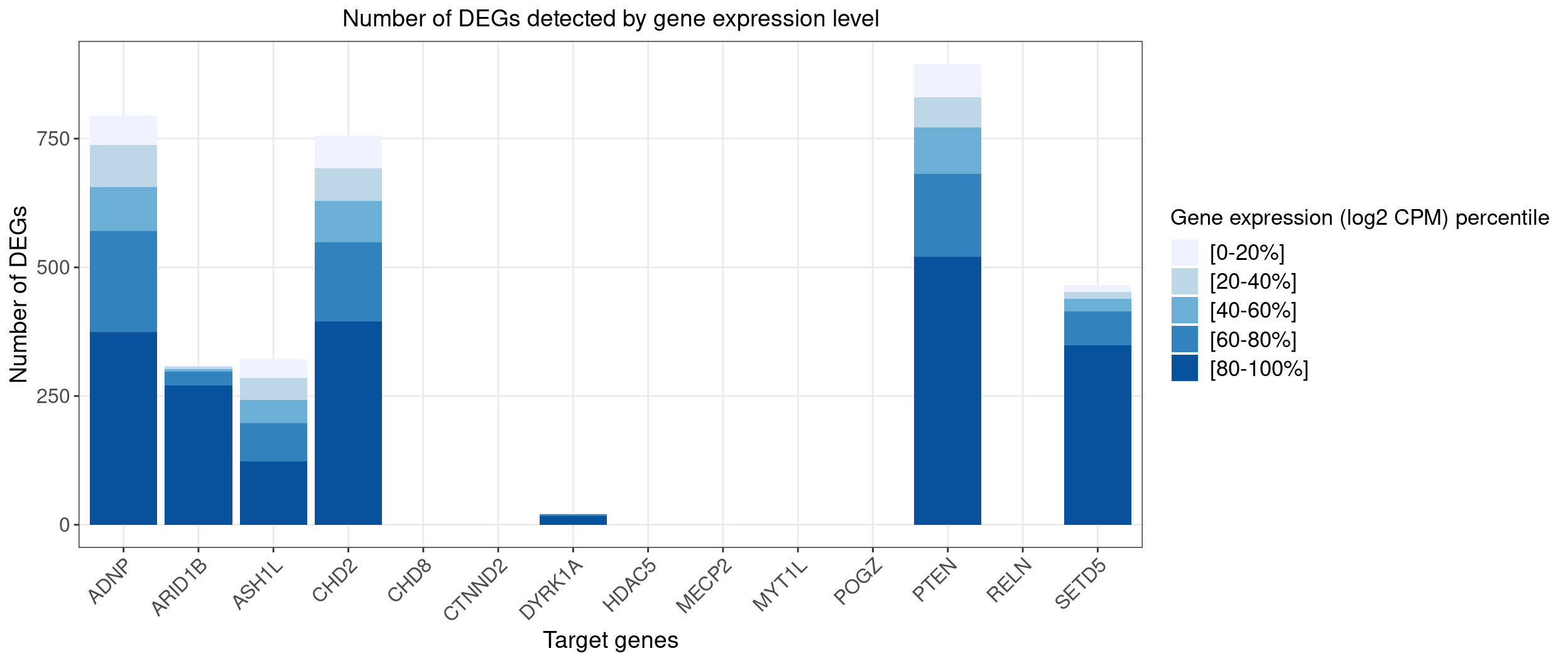
# dev.off()
1 2 3 4 5
1200 1200 1200 1200 1200
1200 genes in bin 1
1200 genes in bin 2
1200 genes in bin 3
1200 genes in bin 4
1200 genes in bin 5
Total number of DEGs:
ADNP ARID1B ASH1L CHD2 CHD8 CTNND2 DYRK1A HDAC5 MECP2 MYT1L POGZ
795 310 322 756 0 0 23 0 0 0 0
PTEN RELN SETD5
895 0 466 T cells data
Load input data
combined_obj <- readRDS('/project2/xinhe/yifan/Factor_analysis/shared_data/TCells_cropseq_data_seurat.rds')Extract data for stimulated cells
metadata <- combined_obj@meta.data
table(metadata$orig.ident)
combined_obj@meta.data$condition <- "unstimulated"
combined_obj@meta.data$condition[which(endsWith(combined_obj@meta.data$orig.ident, "S"))] <- "stimulated"
combined_obj <- subset(combined_obj, subset = condition == "stimulated")
combined_obj
table(combined_obj@meta.data$orig.ident)
dim(combined_obj)
TCells_D1N TCells_D1S TCells_D2N TCells_D2S
5533 6843 5144 7435
An object of class Seurat
33694 features across 14278 samples within 1 assay
Active assay: RNA (33694 features, 1000 variable features)
2 dimensional reductions calculated: pca, umap
TCells_D1S TCells_D2S
6843 7435
[1] 33694 14278Normalizing the data
combined_obj <- NormalizeData(combined_obj, scale.factor = 1e6)
log2cpm_exp_mat <- GetAssayData(combined_obj) / log(2)Select the 6k genes used for GSFA in this analysis
# Normalized and scaled data used for GSFA, the rownames of which are the 6k genes used for GSFA
scaled_gene_matrix_in_gsfa <- combined_obj@assays$RNA@scale.data
selected_gene_ids <- rownames(scaled_gene_matrix_in_gsfa)
log2cpm_exp_mat <- log2cpm_exp_mat[selected_gene_ids, ]
dim(log2cpm_exp_mat)[1] 6000 14278Load GSFA result
data_folder <- "/project2/xinhe/yifan/Factor_analysis/Stimulated_T_Cells/"
fit <- readRDS(paste0(data_folder,
"gsfa_output_detect_01/all_uncorrected_by_group.use_negctrl/All.gibbs_obj_k20.svd_negctrl.restart.light.rds"))
gibbs_PM <- fit$posterior_means
lfsr_mat1 <- fit$lfsr1[, -ncol(fit$lfsr1)]
lfsr_mat0 <- fit$lfsr0[, -ncol(fit$lfsr0)]
total_effect1 <- fit$total_effect1[, -ncol(fit$total_effect1)]
total_effect0 <- fit$total_effect0[, -ncol(fit$total_effect0)]
KO_names <- colnames(lfsr_mat1)
guides <- KO_names[KO_names!="NonTarget"]lfsr_mat <- lfsr_mat1
if(!all.equal(rownames(lfsr_mat), rownames(log2cpm_exp_mat))){stop("Gene names not match!")}
mean_gene_exp <- rowMeans(log2cpm_exp_mat)
exp_breaks <- quantile(mean_gene_exp, probs = seq(0,1,0.2))
gene_exp_bins <- cut(mean_gene_exp, breaks = exp_breaks, labels = 1:5)
gene_exp_bins[is.na(gene_exp_bins)] <- 1
gene_exp_bins.df <- data.frame(geneID = rownames(log2cpm_exp_mat), mean_exp = mean_gene_exp, exp_bin = gene_exp_bins)
table(gene_exp_bins.df$exp_bin)
lfsr_signif_num_bins <- data.frame()
for(l in 1:5){
curr_genes <- gene_exp_bins.df[gene_exp_bins.df$exp_bin == l, ]$geneID
cat(length(curr_genes), "genes in bin", l, "\n")
curr_lfsr_mat <- lfsr_mat[curr_genes, ]
curr_lfsr_signif_num <- colSums(curr_lfsr_mat < 0.05)
lfsr_signif_num_bins <- rbind(lfsr_signif_num_bins,
c(bin = l, curr_lfsr_signif_num))
}
colnames(lfsr_signif_num_bins) <- c("bin", colnames(lfsr_mat))
cat("Total number of DEGs: \n")
colSums(lfsr_signif_num_bins[,guides])
lfsr_signif_num_bins.df <- tidyr::gather(lfsr_signif_num_bins[,c("bin", guides)], guide, num_genes, all_of(guides), factor_key=TRUE)
lfsr_signif_num_bins.df$bin <- factor(lfsr_signif_num_bins.df$bin, levels = 1:5,
labels = c("[0-20%]", "[20-40%]", "[40-60%]", "[60-80%]", "[80-100%]"))
# pdf(file.path(res_dir, "Tcells_stimulated_lfsr_signif_num_by_exp_bins.pdf"), width = 14, height = 3)
ggplot(lfsr_signif_num_bins.df, aes(x=guide, y=num_genes, fill=bin)) +
geom_bar(position="stack", stat="identity") +
scale_fill_brewer(palette = "Blues") +
guides(fill=guide_legend(title="Gene expression (log2 CPM) percentile")) +
labs(x = "Target genes",
y = "Number of DEGs",
title = "Number of DEGs detected by gene expression level") +
theme(axis.text.x = element_text(angle = 45, hjust = 1, size = 12),
legend.position = "right",
legend.text = element_text(size = 13))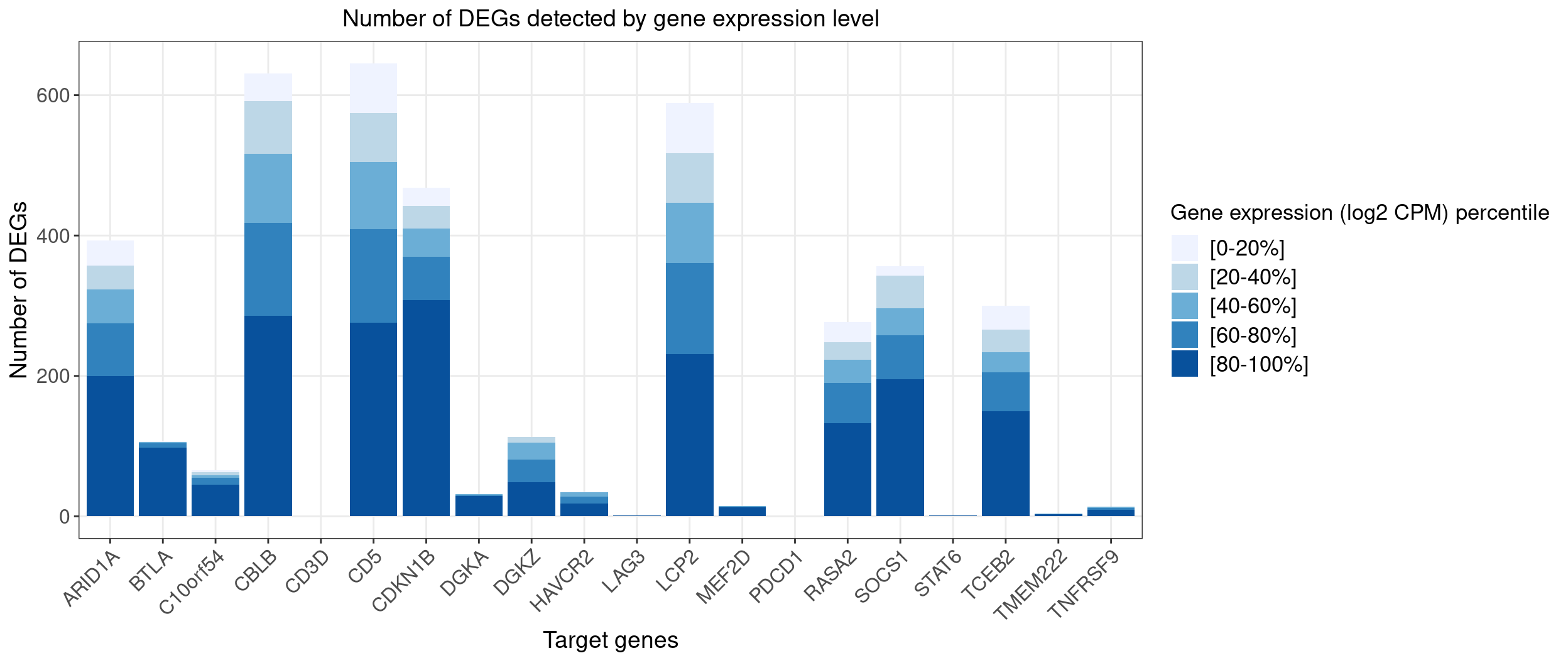
# dev.off()
1 2 3 4 5
1200 1200 1200 1200 1200
1200 genes in bin 1
1200 genes in bin 2
1200 genes in bin 3
1200 genes in bin 4
1200 genes in bin 5
Total number of DEGs:
ARID1A BTLA C10orf54 CBLB CD3D CD5 CDKN1B DGKA
393 107 66 631 0 645 468 32
DGKZ HAVCR2 LAG3 LCP2 MEF2D PDCD1 RASA2 SOCS1
113 35 1 589 15 0 277 356
STAT6 TCEB2 TMEM222 TNFRSF9
1 300 4 14 Session Information
sessionInfo()R version 4.0.4 (2021-02-15)
Platform: x86_64-pc-linux-gnu (64-bit)
Running under: Scientific Linux 7.4 (Nitrogen)
Matrix products: default
BLAS/LAPACK: /software/openblas-0.3.13-el7-x86_64/lib/libopenblas_haswellp-r0.3.13.so
locale:
[1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C
[3] LC_TIME=en_US.UTF-8 LC_COLLATE=en_US.UTF-8
[5] LC_MONETARY=en_US.UTF-8 LC_MESSAGES=en_US.UTF-8
[7] LC_PAPER=en_US.UTF-8 LC_NAME=C
[9] LC_ADDRESS=C LC_TELEPHONE=C
[11] LC_MEASUREMENT=en_US.UTF-8 LC_IDENTIFICATION=C
attached base packages:
[1] grid stats graphics grDevices utils datasets methods
[8] base
other attached packages:
[1] lattice_0.20-45 GSFA_0.2.8 WebGestaltR_0.4.4
[4] kableExtra_1.3.4 ComplexHeatmap_2.6.2 gridExtra_2.3
[7] forcats_0.5.1 stringr_1.4.0 dplyr_1.0.8
[10] purrr_0.3.4 readr_2.1.2 tidyr_1.2.0
[13] tibble_3.1.6 ggplot2_3.3.5 tidyverse_1.3.1
[16] Matrix_1.4-1 data.table_1.14.2 SeuratObject_4.0.4
[19] Seurat_4.1.0 workflowr_1.7.0
loaded via a namespace (and not attached):
[1] utf8_1.2.2 reticulate_1.25 tidyselect_1.1.2
[4] htmlwidgets_1.5.4 Rtsne_0.15 munsell_0.5.0
[7] codetools_0.2-18 ica_1.0-2 future_1.24.0
[10] miniUI_0.1.1.1 withr_2.5.0 spatstat.random_2.1-0
[13] colorspace_2.0-3 highr_0.9 knitr_1.38
[16] rstudioapi_0.13 stats4_4.0.4 ROCR_1.0-11
[19] tensor_1.5 listenv_0.8.0 labeling_0.4.2
[22] git2r_0.30.1 polyclip_1.10-0 farver_2.1.1
[25] rprojroot_2.0.2 parallelly_1.32.1 vctrs_0.4.1
[28] generics_0.1.3 xfun_0.30 R6_2.5.1
[31] doParallel_1.0.17 clue_0.3-60 spatstat.utils_2.3-0
[34] assertthat_0.2.1 promises_1.2.0.1 scales_1.2.0
[37] gtable_0.3.0 Cairo_1.6-0 globals_0.16.0
[40] processx_3.5.3 goftest_1.2-3 rlang_1.0.4
[43] systemfonts_1.0.4 GlobalOptions_0.1.2 splines_4.0.4
[46] lazyeval_0.2.2 spatstat.geom_2.3-2 broom_0.8.0
[49] yaml_2.3.5 reshape2_1.4.4 abind_1.4-5
[52] modelr_0.1.8 backports_1.4.1 httpuv_1.6.5
[55] tools_4.0.4 ellipsis_0.3.2 spatstat.core_2.4-0
[58] jquerylib_0.1.4 RColorBrewer_1.1-3 BiocGenerics_0.36.1
[61] ggridges_0.5.3 Rcpp_1.0.9 plyr_1.8.6
[64] ps_1.7.1 rpart_4.1-15 deldir_1.0-6
[67] pbapply_1.5-0 GetoptLong_1.0.5 cowplot_1.1.1
[70] S4Vectors_0.28.1 zoo_1.8-9 haven_2.5.0
[73] ggrepel_0.9.1 cluster_2.1.3 fs_1.5.2
[76] apcluster_1.4.10 magrittr_2.0.3 scattermore_0.7
[79] circlize_0.4.15 lmtest_0.9-40 reprex_2.0.1
[82] RANN_2.6.1 whisker_0.4 fitdistrplus_1.1-8
[85] matrixStats_0.62.0 hms_1.1.1 patchwork_1.1.1
[88] mime_0.12 evaluate_0.16 xtable_1.8-4
[91] readxl_1.4.0 IRanges_2.24.1 shape_1.4.6
[94] compiler_4.0.4 KernSmooth_2.23-20 crayon_1.5.1
[97] htmltools_0.5.3 mgcv_1.8-39 later_1.3.0
[100] tzdb_0.3.0 lubridate_1.8.0 DBI_1.1.3
[103] dbplyr_2.1.1 MASS_7.3-58.1 cli_3.3.0
[106] parallel_4.0.4 igraph_1.3.4 pkgconfig_2.0.3
[109] getPass_0.2-2 plotly_4.10.0 spatstat.sparse_2.1-0
[112] xml2_1.3.3 foreach_1.5.2 svglite_2.0.0
[115] bslib_0.3.1 rngtools_1.5.2 webshot_0.5.2
[118] rvest_1.0.2 doRNG_1.8.2 callr_3.7.0
[121] digest_0.6.29 sctransform_0.3.3 RcppAnnoy_0.0.19
[124] spatstat.data_2.1-2 rmarkdown_2.13 cellranger_1.1.0
[127] leiden_0.3.9 uwot_0.1.11 shiny_1.7.1
[130] rjson_0.2.21 lifecycle_1.0.1 nlme_3.1-159
[133] jsonlite_1.8.0 viridisLite_0.4.0 fansi_1.0.3
[136] pillar_1.8.0 fastmap_1.1.0 httr_1.4.2
[139] survival_3.3-1 glue_1.6.2 png_0.1-7
[142] iterators_1.0.14 stringi_1.7.6 sass_0.4.1
[145] irlba_2.3.5 future.apply_1.8.1
sessionInfo()R version 4.0.4 (2021-02-15)
Platform: x86_64-pc-linux-gnu (64-bit)
Running under: Scientific Linux 7.4 (Nitrogen)
Matrix products: default
BLAS/LAPACK: /software/openblas-0.3.13-el7-x86_64/lib/libopenblas_haswellp-r0.3.13.so
locale:
[1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C
[3] LC_TIME=en_US.UTF-8 LC_COLLATE=en_US.UTF-8
[5] LC_MONETARY=en_US.UTF-8 LC_MESSAGES=en_US.UTF-8
[7] LC_PAPER=en_US.UTF-8 LC_NAME=C
[9] LC_ADDRESS=C LC_TELEPHONE=C
[11] LC_MEASUREMENT=en_US.UTF-8 LC_IDENTIFICATION=C
attached base packages:
[1] grid stats graphics grDevices utils datasets methods
[8] base
other attached packages:
[1] lattice_0.20-45 GSFA_0.2.8 WebGestaltR_0.4.4
[4] kableExtra_1.3.4 ComplexHeatmap_2.6.2 gridExtra_2.3
[7] forcats_0.5.1 stringr_1.4.0 dplyr_1.0.8
[10] purrr_0.3.4 readr_2.1.2 tidyr_1.2.0
[13] tibble_3.1.6 ggplot2_3.3.5 tidyverse_1.3.1
[16] Matrix_1.4-1 data.table_1.14.2 SeuratObject_4.0.4
[19] Seurat_4.1.0 workflowr_1.7.0
loaded via a namespace (and not attached):
[1] utf8_1.2.2 reticulate_1.25 tidyselect_1.1.2
[4] htmlwidgets_1.5.4 Rtsne_0.15 munsell_0.5.0
[7] codetools_0.2-18 ica_1.0-2 future_1.24.0
[10] miniUI_0.1.1.1 withr_2.5.0 spatstat.random_2.1-0
[13] colorspace_2.0-3 highr_0.9 knitr_1.38
[16] rstudioapi_0.13 stats4_4.0.4 ROCR_1.0-11
[19] tensor_1.5 listenv_0.8.0 labeling_0.4.2
[22] git2r_0.30.1 polyclip_1.10-0 farver_2.1.1
[25] rprojroot_2.0.2 parallelly_1.32.1 vctrs_0.4.1
[28] generics_0.1.3 xfun_0.30 R6_2.5.1
[31] doParallel_1.0.17 clue_0.3-60 spatstat.utils_2.3-0
[34] assertthat_0.2.1 promises_1.2.0.1 scales_1.2.0
[37] gtable_0.3.0 Cairo_1.6-0 globals_0.16.0
[40] processx_3.5.3 goftest_1.2-3 rlang_1.0.4
[43] systemfonts_1.0.4 GlobalOptions_0.1.2 splines_4.0.4
[46] lazyeval_0.2.2 spatstat.geom_2.3-2 broom_0.8.0
[49] yaml_2.3.5 reshape2_1.4.4 abind_1.4-5
[52] modelr_0.1.8 backports_1.4.1 httpuv_1.6.5
[55] tools_4.0.4 ellipsis_0.3.2 spatstat.core_2.4-0
[58] jquerylib_0.1.4 RColorBrewer_1.1-3 BiocGenerics_0.36.1
[61] ggridges_0.5.3 Rcpp_1.0.9 plyr_1.8.6
[64] ps_1.7.1 rpart_4.1-15 deldir_1.0-6
[67] pbapply_1.5-0 GetoptLong_1.0.5 cowplot_1.1.1
[70] S4Vectors_0.28.1 zoo_1.8-9 haven_2.5.0
[73] ggrepel_0.9.1 cluster_2.1.3 fs_1.5.2
[76] apcluster_1.4.10 magrittr_2.0.3 scattermore_0.7
[79] circlize_0.4.15 lmtest_0.9-40 reprex_2.0.1
[82] RANN_2.6.1 whisker_0.4 fitdistrplus_1.1-8
[85] matrixStats_0.62.0 hms_1.1.1 patchwork_1.1.1
[88] mime_0.12 evaluate_0.16 xtable_1.8-4
[91] readxl_1.4.0 IRanges_2.24.1 shape_1.4.6
[94] compiler_4.0.4 KernSmooth_2.23-20 crayon_1.5.1
[97] htmltools_0.5.3 mgcv_1.8-39 later_1.3.0
[100] tzdb_0.3.0 lubridate_1.8.0 DBI_1.1.3
[103] dbplyr_2.1.1 MASS_7.3-58.1 cli_3.3.0
[106] parallel_4.0.4 igraph_1.3.4 pkgconfig_2.0.3
[109] getPass_0.2-2 plotly_4.10.0 spatstat.sparse_2.1-0
[112] xml2_1.3.3 foreach_1.5.2 svglite_2.0.0
[115] bslib_0.3.1 rngtools_1.5.2 webshot_0.5.2
[118] rvest_1.0.2 doRNG_1.8.2 callr_3.7.0
[121] digest_0.6.29 sctransform_0.3.3 RcppAnnoy_0.0.19
[124] spatstat.data_2.1-2 rmarkdown_2.13 cellranger_1.1.0
[127] leiden_0.3.9 uwot_0.1.11 shiny_1.7.1
[130] rjson_0.2.21 lifecycle_1.0.1 nlme_3.1-159
[133] jsonlite_1.8.0 viridisLite_0.4.0 fansi_1.0.3
[136] pillar_1.8.0 fastmap_1.1.0 httr_1.4.2
[139] survival_3.3-1 glue_1.6.2 png_0.1-7
[142] iterators_1.0.14 stringi_1.7.6 sass_0.4.1
[145] irlba_2.3.5 future.apply_1.8.1